
La compilation n'est pas une science occulte
Note de l'éditeur (2026) > Ce article est extrait du livre Coder efficacement – Bonnes pratiques et erreurs à éviter (en C++) de Philippe Dunski, publié en 2014. Les fondamentaux de la chaîne de compilation qu'il décrit sont toujours pleinement valides aujourd'hui. En revanche, avec l'introduction des modules dans le C++20, le modèle "inclusion textuelle bête et fichier sans mémoire" n'est plus le seul modèle qui a cours. Aussi avons-nous complété le texte original pour tenir compte de l'outillage moderne (Clang/LLVM) et des évolutions du langage (modules C++20).
 Table des matières
Table des matières ")
J'ai, parfois, l'impression que de nombreux développeurs envisagent le travail du compilateur comme une sorte de phénomène magique, sans comprendre le moins du monde les processus que cela implique.
Vous commencez sans doute à connaître la chanson : il n'est pas dans mes intentions de vous apprendre dans ce chapitre à créer votre propre chaîne de compilation car il faudrait un livre entier pour y arriver. Mon objectif ici est simplement de vous faire comprendre les grandes lignes de la chaîne d'outils qui sont utilisés pour transformer votre code en une application exécutable.
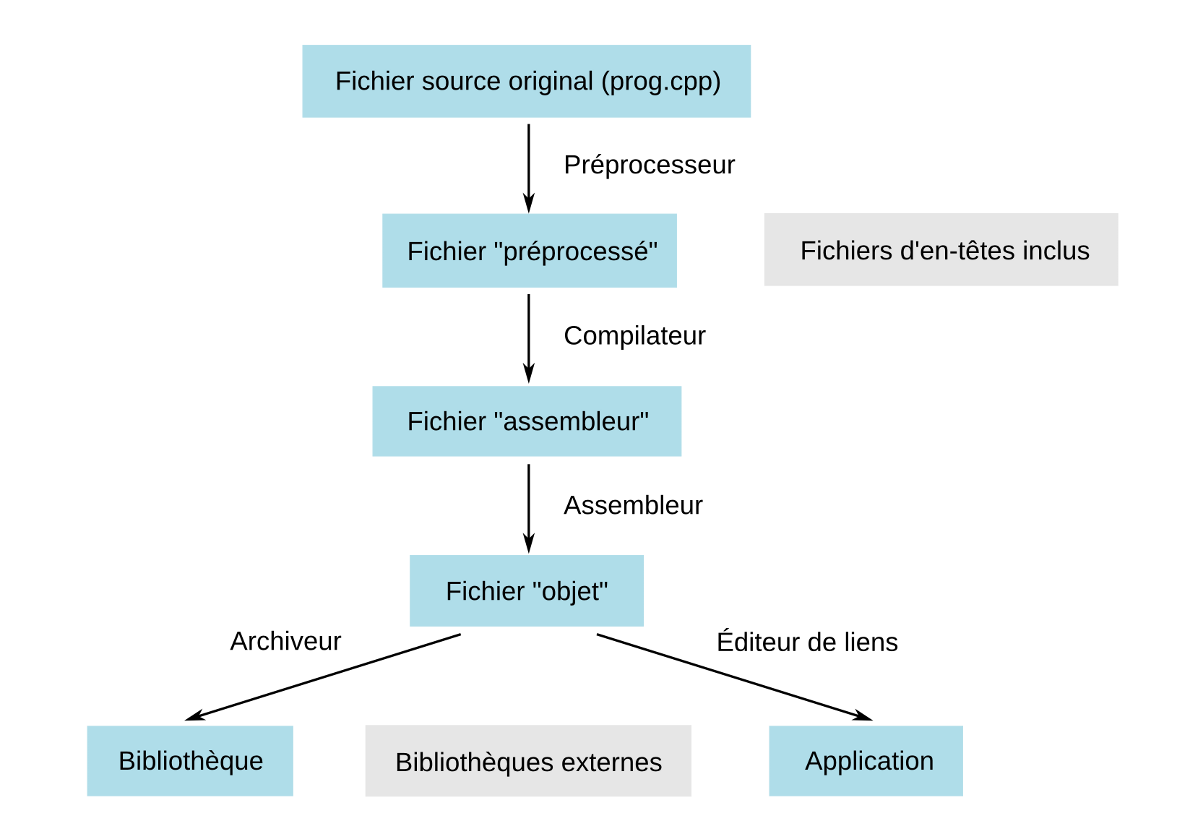
Le processus de compilation se divise en quatre grandes étapes comme l'indique le schéma ci-dessous. Chaque étape est prise en charge par un outil particulier.
Le préprocesseur : quelques commandes simples
La première étape subie par votre code lorsque vous le compilez est le passage du préprocesseur. Il s'agit d'un outil capable d'effectuer quelques macros (des commandes vraiment simples) en vue de préparer la compilation.
La directive #include aura pour résultat de remplacer cette macro par le contenu intégral du fichier dont le nom est donné par la directive avant que le compilateur n'aille plus loin dans le code. De cette manière, le contenu du fichier inclus sera lui-même analysé par le compilateur, et, si une autre directive #include est rencontrée, elle sera elle aussi remplacée par le contenu du fichier indiqué et ainsi de suite.
La deuxième sorte de macros qui nous intéresse ici sont les macros dites de compilation conditionnelle : #if, #ifdef, #ifndef, #else et #elif. Elles auront pour résultat de vérifier si une condition est remplie et de garder (ou de supprimer) les parties de code correspondantes en fonction du résultat de la condition.
Enfin, le préprocesseur remplacera les différents symboles qu'il reconnaît (définis par la directive #define) par le code correspondant à la définition de ces symboles.
Le préprocesseur utilise généralement un pipe pour travailler, ce qui fait qu'un fichier temporaire ne sera pas forcément créé : le résultat final de son travail est généralement directement disponible en mémoire pour la suite du travail.
Si vous utilisez la suite GCC, vous pouvez assez facilement vous faire une idée du résultat du passage du préprocesseur en invoquant la commande :
g++ -c fichier.cpp -o fichier.pre -E
Si vous utilisez Clang (installé par défaut sur macOS et disponible sur Linux), la commande équivalente est :
clang++ -c fichier.cpp -o fichier.pre -E
Ensuite, ouvrez le fichier qui résulte de l'opération avec votre éditeur de texte préféré.
Mais attention les yeux : le résultat est très largement plus gros que le code du fichier d'origine. Ainsi, un code aussi simple que :
#include <iostream>
int main(){
std::cout << "hello world" << std::endl;
return 0;
}
aura pour résultat la génération d'un fichier de près de 17 000 lignes à cause des inclusions en cascade occasionnées par l'inclusion de <iostream>.
Un programme pour écrire des programmes
Une fois que le préprocesseur a fini son travail, c'est au tour du compilateur en lui-même de prendre le relais.
Il s'agit de comprendre ici qu'un compilateur n'est jamais qu'un "traducteur universel" dont le but est de traduire votre code source d'un langage (C++ en l'occurrence) dans un autre langage qui sera utilisé pour la suite (le langage assembleur, en l'occurrence).
Bien qu'elles n'apparaissent pas sur le schéma, on peut distinguer quatre grandes étapes lors de la compilation proprement dite :
-
l'analyse lexicale ;
-
un certain nombre d'optimisations éventuelles ;
Les deux premières étapes sont généralement prises en charge par ce que l'on appelle le front end, la dernière étant prise en charge par ce que l'on appelle, assez logiquement, le back end.
Quant aux optimisations, il est assez difficile d'en indiquer la place exacte. Certaines, spécifiques à un langage particulier, prendront place dans le front end, alors que d'autres, plus générales, prendront place dans le back end.
Si l'on fait la distinction entre le front end et le back end, c'est parce que le premier va avoir pour objectif de transformer la logique dont le code est la représentation que vous en avez donnée dans un langage bien spécifique (ici, on parle de C++, mais il pourrait y avoir un front end pour n'importe quel autre langage) en une représentation commune qui pourra être manipulée par le second quel que soit le langage d'origine.
L'analyse lexicale
L'analyse lexicale a pour but de diviser votre code en un certain nombre de tokens ou lexèmes. Autrement dit, de diviser votre code en une multitude de petits groupes de lettres et de symboles, et de donner un sens particulier à chacun de ces groupes.
L'analyse syntaxique
Les ordinateurs ont un très gros désavantage sur les humains : ils n'ont strictement aucune imagination, et aucune intelligence autre que celle que le développeur a été en mesure (ou a bien voulu) lui donner.
Une edute a mmêe drtnoméé la cticapaé hniamue à crdnerpmoe un ttxee à pitrar du mnemot où tetuos les lerttes d'un mot snot ptnesérs, tnat que la prèimere et la drèinree lrttee snot bein peécals
Alors qu'un humain est parfaitement capable de comprendre quelqu'un qui s'adresse à lui en faisant des fautes de syntaxe ou de grammaire, l'ordinateur sera totalement incapable de comprendre un texte qui ne respecte pas strictement la syntaxe et la grammaire auxquelles il s'attend.
Vous avez sûrement dû vous concentrer un peu sur la citation précédente, mais vous avez très certainement été en mesure d'en comprendre le sens (une étude a même démontré la capacité humaine à comprendre un texte à partir du moment où toutes les lettres d'un mot sont présentes, tant que la première et la dernière lettre sont bien placées). Un ordinateur ne sera jamais capable d'une telle compréhension.
Et comme l'idée générale d'un compilateur (ou d'un interpréteur, pour d'autres langages) est quand même de traduire les instructions fournies par votre code en d'autres instructions, si le compilateur ne comprend pas ce que vous voulez, il sera purement et simplement dans l'impossibilité de faire son travail.
Une fois que les différents lexèmes auront été trouvés, le compilateur va chercher la plus grande suite de lexèmes qu'il est en mesure de comprendre, afin de pouvoir la manipuler de manière plus ou moins atomique.
Là encore, si, en raison d'un lexème mal placé, il ne trouve aucune suite qu'il puisse interpréter, il ne sera pas en mesure de faire son travail, et c'est généralement à ce moment-là que les erreurs de compilation surviendront.
Les optimisations
Peut-être n'en avez-vous pas conscience, mais un processeur dispose d'un jeu d'instructions assez limité.
Chaque instruction qui lui est transmise va prendre un certain temps qui correspond au nombre de cycles d'horloge dont le processeur a besoin pour effectuer l'instruction en question. Vous n'aurez donc pas de mal à comprendre que plus le nombre d'instructions qu'un processeur doit effectuer est important, plus il mettra du temps à obtenir le résultat souhaité. On peut d'ailleurs exprimer la chose de manière inverse : moins le processeur devra effectuer d'instructions, plus le résultat viendra rapidement. L'idée reste strictement la même.
Avant de générer le code assembleur définitif, de nombreux compilateurs vont donc essayer d'optimiser au mieux, à l'aide de différents algorithmes, la représentation du code dont ils disposent, et cela toujours dans un seul but : obtenir au final l'exécution la plus rapide possible.
Générer le code assembleur
La dernière chose que le compilateur prendra en charge sera la génération de code dans un langage nommé assembleur. Il s'agit d'un langage particulièrement proche des instructions que le processeur est en mesure de comprendre, dans lequel chaque instruction processeur est représentée par ce que l'on appelle un mnémonique.
Une fois le code en assembleur généré, il est transmis (généralement par pipe) à l'outil suivant.
Si vous utilisez GCC, vous pouvez vous faire une idée précise du résultat en invoquant la commande :
g++ -c fichier.cpp -o fichier.asm -S
Avec Clang, la commande équivalente est :
clang++ -c fichier.cpp -o fichier.asm -S
L'assembleur
L'assembleur est un outil qui va transformer le code assembleur en code binaire.
En effet, le processeur n'est capable de comprendre que des successions de 0 et de 1. Toutes les instructions effectuées par le processeur ne seront jamais qu'une succession de 0 et de 1 dans un ordre bien particulier correspondant à une instruction bien particulière.
Le fichier qui résulte de cette transformation est ce que l'on appelle un fichier objet.
Note > Si, à ce stade, vous ne deviez avoir qu'un seul fichier intermédiaire, ce serait forcément le fichier objet généré par l'assembleur. Il est possible que même ce fichier ne soit pas écrit sur le disque dur et qu'il soit lui aussi transmis par pipe pour la suite du traitement, mais les méthodes actuelles de compilation ont malgré tout tendance à faire en sorte que ce ne soit fait ainsi que de manière exceptionnelle.
Un fichier à la fois
Ces différentes étapes accomplies, la compilation proprement dite est terminée.
Notez cependant que cela ne veut absolument pas dire que nous disposons déjà de l'application exécutable, cela signifie juste que le plus gros du travail, qui consistait à créer une succession d'instructions compréhensibles par le processeur à partir de votre code, est maintenant fait.
Notez bien que toutes ces étapes sont effectuées fichier par fichier. En effet, si vous avez dix fichiers dans votre projet, le compilateur les effectue d'abord pour le premier fichier, puis pour le deuxième et ainsi de suite pour les dix fichiers de votre projet.
Attention > Il est très important de comprendre que le compilateur ne garde strictement aucune mémoire de ce qu'il a pu faire lors du traitement du fichier précédent ! Chaque fichier est traité comme une entité propre pour laquelle tout est systématiquement remis à zéro lorsqu'il passe d'un fichier à l'autre. Ce n'est donc pas parce que le compilateur a connaissance d'un élément particulier lorsqu'il s'occupe du fichier A qu'il en aura connaissance lorsqu'il s'occupera du fichier B, bien au contraire.
Note C++20 > Ce modèle "un fichier à la fois, sans mémoire" décrit le fonctionnement classique basé sur les fichiers d'en-tête (.h / .hpp). C++20 introduit les modules (import std;, import <iostream>;…), un mécanisme différent qui permet au compilateur de partager des informations entre unités de traduction de façon contrôlée. Les modules font l'objet d'un article séparé.
L'édition de liens
Nous arrivons maintenant à la dernière étape, appelée édition de liens. Elle consiste à regrouper dans un seul et unique fichier compréhensible par le processeur l'ensemble des fichiers objets générés par le compilateur.
L'idée de base est la suivante : lorsque le compilateur sait que quelque chose existe (par exemple, l'opérateur << pour la classe std::ostream) mais qu'il n'a pas généré le code pour ce "quelque chose", il place un symbole identifiant ce "quelque chose" de manière strictement unique et non ambiguë dans le code binaire qu'il a généré. Il s'agit maintenant de faire le lien entre ces différents symboles et le code binaire qui correspond à ces différents symboles.
L'éditeur de liens va donc regrouper les différents fragments de code binaire qu'il trouvera dans les différents fichiers objets qu'on lui indique en un seul fichier et remplacer chaque symbole par l'adresse à laquelle se trouve le symbole en question dans le code binaire.
Il est possible de demander à l'éditeur de liens d'utiliser du code binaire qui a été généré en dehors du projet et qui est disponible sous la forme de bibliothèques. Ces bibliothèques ne sont jamais que des archives dans lesquelles du code binaire a été placé afin de fournir certaines fonctionnalités particulières.
On distingue deux types de bibliothèques. Les bibliothèques statiques (extensions .a sous Linux/macOS, .lib sous Windows) voient leur code intégré directement dans l'exécutable final : celui-ci est autonome, mais plus volumineux. Les bibliothèques dynamiques (extensions .so sous Linux, .dylib sous macOS, .dll sous Windows) restent des fichiers séparés chargés au moment de l'exécution : l'exécutable est plus léger, mais il a besoin que ces fichiers soient présents sur la machine cible.
Note > Bibliothèque est la traduction correcte du terme anglais library. Ce n'est donc pas une librairie qu'il vous faut lorsque vous cherchez une fonctionnalité que vous ne voulez pas implémenter par vous-même, mais bien une bibliothèque.
Si l'éditeur de liens ne trouve nulle part le code binaire qui correspond à un symbole particulier, il ne pourra, vous vous en doutez désormais, pas terminer son travail et s'arrêtera sur une erreur dont le but est de vous indiquer ce qui lui manque pour y arriver. Le message d'erreur sera, généralement, proche de undefined reference to <un symbole quelconque>.
Voir aussi
➤ Coder efficacement – Bonnes pratiques et erreurs à éviter (en C++) écrit par Philippe Dunski
➤ Le guide du C++ - de débutant à développeur (C++23) écrit par Benoît Vittupier et Mehdi Benharrats